
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░č鹊čĆčüą║ąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣
 ą«čĆąĖą╣ ąæčāčéčŗą╗čīčüą║ąĖą╣
ą«čĆąĖą╣ ąæčāčéčŗą╗čīčüą║ąĖą╣
 ą¤ą░ą▓ąĄą╗ ąŚąĄčĆąĮąŠą▓
ą¤ą░ą▓ąĄą╗ ąŚąĄčĆąĮąŠą▓
ąÆąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ąĮą░čĆčÅą┤čā čü č鹥ą╗ąĄč乊ąĮąĮąŠą╣ čüąĄčéčīčÄ ąŠą▒čēąĄą│ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ (ąóążą×ą¤) ą▓čüąĄ čłąĖčĆąĄ ąĖ čłąĖčĆąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ č鹥čģąĮąŠą╗ąŠą│ąĖčÅ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ č鹥ą╗ąĄč乊ąĮąĖąĖ VoIP ąĮą░ ą▒ą░ąĘąĄ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ čüąĄčéąĖ ąśąĮč鹥čĆąĮąĄčé. ąŻčćąĖčéčŗą▓ą░čÅ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮąŠčüčéčī čüąĄčéąĖ ąśąĮč鹥čĆąĮąĄčé ąĖ ą┐čĆąŠč鹊ą║ąŠą╗ą░ TCP/IP, ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ VoIP ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé: ą▓ąŠ-ą┐ąĄčĆą▓čŗčģ, ąŠčģą▓ą░čéąĖčéčī ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣, ą▓ąŠ-ą▓č鹊čĆčŗčģ, čüąĮąĖąĘąĖčéčī, ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ąóążą×ą¤ (čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ čåąĖčäčĆąŠą▓čŗąĄ čüąĖčüč鹥ą╝čŗ, čéą░ą║ ą║ą░ą║ čüčĆą░ą▓ąĮąĄąĮąĖąĄ č鹥čģąĮąŠą╗ąŠą│ąĖą╣ VoIP ąĖ ą░ąĮą░ą╗ąŠą│ąŠą▓ąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ąĮąĄ čāą╝ąĄčüčéąĮąŠ), ąŠą▒čŖąĄą╝ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą▓ ą║ą░ąĮą░ą╗ čüą▓čÅąĘąĖ ą┤ą░ąĮąĮčŗčģ. ąÆ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖčéčī, čćč鹊, ą║ą░ą║ č鹊ą╗čīą║ąŠ ąśąĮč鹥čĆąĮąĄčé ąŠą▒ąĄčüą┐ąĄčćąĖčé ą┤ąŠčüčéą░ą▓ą║čā ą│ąŠą╗ąŠčüą░ čü ą║ą░č湥čüčéą▓ąŠą╝, čüčĆą░ą▓ąĮąĖą╝čŗą╝ čü č鹥ą╝, čćč鹊 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé č鹥ą╗ąĄč乊ąĮąĮą░čÅ čüą▓čÅąĘčī, ąóążą×ą¤ ą╝ąŠąČąĄčé ąŠčēčāčéąĖčéčī ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāčüąĖą╗ąĖą▓čłčāčÄčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÄ čüąŠ čüč鹊čĆąŠąĮčŗ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ VoIP.
ą×ą┤ąĮąĖą╝ ąĖąĘ ą▒ą░ąĘąŠą▓čŗčģ ą┐čĆąĖąĮčåąĖą┐ąŠą▓ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ čüąĄč鹥ą╣ TCP/IP čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ. ą¤ąŠčŹč鹊ą╝čā čüąĄą╣čćą░čü ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüą║ą░ąĘą░čéčī, ą║ą░ą║ čĆą░čüčéčāčēąĖą╣ VoIP-čéčĆą░čäąĖą║ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠą▒čēčāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čüąĄčéąĖ. ąÆ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ą┐čĆąĄą▓čŗčłąĄąĮąĖąĄ ąĖą╝ąĄčÄčēąĄą╣čüčÅ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą╝ą░ą│ąĖčüčéčĆą░ą╗čīąĮąŠą╣ čüąĄčéąĖ čéą░ą║ąŠą▓ąŠ, čćč鹊 ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé ą┐čĆąĖąĄą╝ą╗ąĄą╝ąŠąĄ ą║ą░č湥čüčéą▓ąŠ ą┤ą░ąČąĄ ą▓ čāčüą╗ąŠą▓ąĖčÅčģ ąĮąĄą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ. ąØąŠ ą║ą░ą║ą░čÅ ą▒čŗ ą▒ąŠą╗čīčłą░čÅ ą┐ąŠą╗ąŠčüą░ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ąĮąĖ ą▒čŗą╗ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮą░, ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą▒čāą┤ąĄčé ą┤ąŠčüčéąĖą│ąĮčāčé ąĄąĄ ą┐čĆąĄą┤ąĄą╗. ą¤ąŠčŹč鹊ą╝čā čü čĆąŠčüč鹊ą╝ čćąĖčüą╗ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ čāčüą╗čāą│ąĖ VoIP ą▒čāą┤ąĄčé čāą▓ąĄą╗ąĖčćąĖą▓ą░čéčīčüčÅ ąĖ ąŠą▒čŖąĄą╝ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ, čćč鹊 ą┐ąŠčéčĆąĄą▒čāąĄčé ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąĮąŠą▓čŗčģ ą╝ąĄč鹊ą┤ąŠą▓ čüąČą░čéąĖčÅ.
ąĪčāčēąĄčüčéą▓čāčÄčēąĖąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ čüąČą░čéąĖčÅ čĆąĄčćąĖ ą┐ąŠą┤ąŠčłą╗ąĖ ą║ čüą▓ąŠąĄą╝čā ą┐čĆąĄą┤ąĄą╗čā ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ. ąŻą▓ąĄą╗ąĖč湥ąĮąĖąĄ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčéą░ čüąČą░čéąĖčÅ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐ąŠč鹥čĆčÅą╝ ą║ą░č湥čüčéą▓ą░ čüąĖą│ąĮą░ą╗ą░. ą¤ąŠčŹč鹊ą╝čā ąĮąĄąŠą▒čģąŠą┤ąĖą╝ ąĮąŠą▓čŗą╣ ą┐ąŠą┤čģąŠą┤. ą×ą┤ąĖąĮ ąĖąĘ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą┐ąŠą┤čģąŠą┤ąŠą▓ ą▓ ą┐ąĄčĆąĄą┤ą░č湥 ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ čüąĄčéąĖ ąśąĮč鹥čĆąĮąĄčé ąŠčüąĮąŠą▓ą░ąĮ ąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüą╗ąŠą▓ą░čĆąĄą╣ ąĮą░ ą┐ąĄčĆąĄą┤ą░čÄčēąĄą╣ ąĖ ą┐čĆąĖąĄą╝ąĮąŠą╣ čüč鹊čĆąŠąĮą░čģ [1, 2]. ąØą░čĆčÅą┤čā čü ą┤ąŠčüč鹊ąĖąĮčüčéą▓ąŠą╝, ą░ ąĖą╝ąĄąĮąĮąŠ čüąŠą║čĆą░čēąĄąĮąĖąĄą╝ ąŠą▒čŖąĄą╝ą░ ą┤ą░ąĮąĮčŗčģ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą▓ ą║ą░ąĮą░ą╗ čüą▓čÅąĘąĖ, ąĄą│ąŠ ąĮąĄą┤ąŠčüčéą░čéą║ąŠą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠč鹥čĆčÅ ąĄčüč鹥čüčéą▓ąĄąĮąĮąŠčüčéąĖ čüąĖąĮč鹥ąĘąĖčĆčāąĄą╝ąŠą╣ čĆąĄčćąĖ, č鹊 ąĄčüčéčī čüčģąŠąČąĄčüčéąĖ čü ą│ąŠą╗ąŠčüąŠą╝ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą┤ąĖą║č鹊čĆą░. ą¤ąŠą┤čģąŠą┤ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčé ą┐ąĄčĆąĄą┤ą░čćčā č鹊ą╗čīą║ąŠ čĆąĄčćąĖ, ą╝čāąĘčŗą║čā ąĖą╗ąĖ čłčāą╝čŗ ąŠą║čĆčāąČą░čÄčēąĄą╣ čüčĆąĄą┤čŗ ą┐ąĄčĆąĄą┤ą░čéčī ą┐ąŠ ą║ą░ąĮą░ą╗čā čüą▓čÅąĘąĖ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ, čćč鹊 ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüč乥čĆčŗ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ą║ą░ą║ ą┤ąŠčüč鹊ąĖąĮčüčéą▓ąŠą╝, čéą░ą║ ąĖ ąĮąĄą┤ąŠčüčéą░čéą║ąŠą╝.
ąöą╗čÅ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓čŗčÅą▓ą╗ąĄąĮąĮčŗčģ ąĮąĄą┤ąŠčüčéą░čéą║ąŠą▓ ą┐ąŠą┤čģąŠą┤ą░ [1, 2] ą┐čĆąĄą┤ą╗ą░ą│ą░ąĄčéčüčÅ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĮą░čÅ ąĮą░ čĆąĖčüčāąĮą║ąĄ (čüčéčĆ. 25) čüčéčĆčāą║čéčāčĆąĮą░čÅ ą╝ąŠą┤ąĄą╗čī ą┐čĆąŠčåąĄčüčüąŠą▓ ą│ąĖą▒čĆąĖą┤ąĮąŠą╣ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, ą▓ ąŠčüąĮąŠą▓ąĄ ą║ąŠč鹊čĆąŠą╣ ą╗ąĄąČą░čé čüą║čĆčŗčéčŗąĄ ą╝ą░čĆą║ąŠą▓čüą║ąĖąĄ ą╝ąŠą┤ąĄą╗ąĖ (ąĪą£ą£).

ą£ąŠą┤ąĄą╗čī, ąŠą▒čŖąĄą┤ąĖąĮčÅčÄčēą░čÅ ą▓ čüąĄą▒ąĄ ą┐čĆąĖąĄą╝ąĮčāčÄ, ą┐ąĄčĆąĄą┤ą░čÄčēčāčÄ čüč鹊čĆąŠąĮčŗ ąĖ ą║ą░ąĮą░ą╗ čüą▓čÅąĘąĖ, čüąŠčüč鹊ąĖčé ąĖąĘ ą▒ą╗ąŠą║ąŠą▓, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖčģ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐čĆąŠčåąĄčüčüčŗ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą▓ čüąĖčüč鹥ą╝ąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ. ąóąĄčĆą╝ąĖąĮ "ą│ąĖą▒čĆąĖą┤ąĮą░čÅ ą║ąŠą╝ą┐čĆąĄčüčüąĖčÅ" ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĮą░ąĘą▓ą░ąĮąĖąĖ ą╝ąŠą┤ąĄą╗ąĖ ą┐ąŠč鹊ą╝čā, čćč鹊 ąĄąĄ čüčéčĆčāą║čéčāčĆą░ ąŠą▒čŖąĄą┤ąĖąĮčÅąĄčé ą║ą░ą║ ą║ą╗ą░čüčüąĖč湥čüą║ąĖąĄ, čéą░ą║ ąĖ ąĮąŠą▓čŗąĄ ą╝ąĄč鹊ą┤čŗ čüąČą░čéąĖčÅ ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░.
ąæą╗ąŠą║ ą░ąĮą░ą╗ąĖąĘą░ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą│ąŠ ą▓čģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé čĆą░ąĘą▒ąĖąĄąĮąĖąĄ ą▓čģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ąĮą░ čäčĆą░ą│ą╝ąĄąĮčéčŗ, čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆčŗčģ ą▓ą░čĆčīąĖčĆčāąĄčéčüčÅ ąŠčé čĆą░ąĘą╝ąĄčĆą░ čüą╗ąŠą▓ą░ ą┤ąŠ čĆą░ąĘą╝ąĄčĆą░ č乊ąĮąĄą╝čŗ (čüą╗ąŠą│ą░) ą▓ čüą╗ąŠą▓ąĄ, ąĖ ą▓čŗčÅą▓ą╗čÅąĄčé čéąĖą┐ ą║ą░ąČą┤ąŠą│ąŠ čäčĆą░ą│ą╝ąĄąĮčéą░, č鹊 ąĄčüčéčī ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ąĄą│ąŠ ą╗ąĖą▒ąŠ ą║ą░ą║ čĆąĄčćčī, ą╗ąĖą▒ąŠ ą║ą░ą║ ąĘą▓čāą║. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čäčĆą░ą│ą╝ąĄąĮčé ą┐ąŠčüčéčāą┐ą░ąĄčé ąĮą░ ą┤ą░ą╗čīąĮąĄą╣čłčāčÄ ąŠą▒čĆą░ą▒ąŠčéą║čā čĆą░ąĘąĮčŗą╝ ą┐čĆąŠčåąĄčüčüą░ą╝. ąĀąĄč湥ą▓ąŠą╣ čüąĖą│ąĮą░ą╗ ą┐ąŠčüčéčāą┐ą░ąĄčé ąĮą░ ą▓čģąŠą┤ ą┤ą▓čāčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠą▓: ą┐čĆąŠčåąĄčüčüą░ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ąĖ ą┐čĆąŠčåąĄčüčüą░ ą░ąĮą░ą╗ąĖąĘą░ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║. ą¤ąĄčĆą▓čŗą╣ ą┐čĆąŠčåąĄčüčü ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé čüąŠą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ čäčĆą░ą│ą╝ąĄąĮčéčā čüąĖą│ąĮą░ą╗ą░ ą║ąŠą┤ čüą╗ąŠą▓ą░ ąĖąĘ čüą╗ąŠą▓ą░čĆčÅ. ąöą╗čÅ čŹč鹊ą│ąŠ ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ č乊čĆą╝ąĖčĆčāąĄčéčüčÅ ąĪą£ą£ čäčĆą░ą│ą╝ąĄąĮčéą░ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, ą║ąŠč鹊čĆą░čÅ ąĘą░č鹥ą╝ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü čŹčéą░ą╗ąŠąĮąĮčŗą╝ąĖ ą╝ąŠą┤ąĄą╗čÅą╝ąĖ ąĖąĘ čüą╗ąŠą▓ą░čĆčÅ. ą¤čĆąŠčåąĄčüčü ąĮą░ąĖą▒ąŠą╗ąĄąĄ čĆąĄčüčāčĆčüąŠąĄą╝ą║ąĖą╣, ąĮąŠ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą│ą╗čāą▒ąĖąĮčŗ ąĪą£ą£ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čü ą▓čŗčüąŠą║ąŠą╣ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčīčÄ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ čüąŠą┐ąŠčüčéą░ą▓ąĖčéčī čäčĆą░ą│ą╝ąĄąĮčé čĆąĄčćąĖ čü ą║ąŠą┤ąŠą╝ čüą╗ąŠą▓ą░ ąĖąĘ čüą╗ąŠą▓ą░čĆčÅ.
ąÉąĮą░ą╗ąĖąĘ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗčÅą▓ąĖčéčī ąŠčüąŠą▒ąĄąĮąĮąŠčüčéąĖ čĆąĄčćąĖ ą┤ąĖą║č鹊čĆą░, ą║ąŠč鹊čĆčŗąĄ ą▓ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ą▒čāą┤čāčé ą┐ąĄčĆąĄą┤ą░ąĮčŗ ąĮą░ ą┐čĆąĖąĄą╝ąĮčāčÄ čüč鹊čĆąŠąĮčā ą▓ ą▓ąĖą┤ąĄ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖčģ ą╝ą░čéčĆąĖčå ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮčŗ ą┤ą╗čÅ čüąĖąĮč鹥ąĘą░ ąĖčüčģąŠą┤ąĮąŠą╣ čĆąĄčćąĖ čü čāč湥č鹊ą╝ č鹥ą╝ą▒čĆą░ą╗čīąĮčŗčģ ąĖ ą┐čüąĖčģąŠčŹą╝ąŠčåąĖąŠąĮą░ą╗čīąĮčŗčģ ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣ ą│ąŠą╗ąŠčüą░ č湥ą╗ąŠą▓ąĄą║ą░. ą¤ąŠą╗čāč湥ąĮąĮčŗąĄ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą║ąŠą┤čŗ čüą╗ąŠą▓ ąĖą╗ąĖ č乊ąĮąĄą╝ ąĖąĮą║ą░ą┐čüčāą╗ąĖčĆčāčÄčéčüčÅ ą▓ ą║ą░ą┤čĆčŗ ą┐čĆąŠč鹊ą║ąŠą╗ą░ TCP/IP ą▓ ą┐čĆąŠčåąĄčüčüąĄ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ą░ą║ąĄč鹊ą▓. ążčĆą░ą│ą╝ąĄąĮčéčŗ ą▓čģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ąĘą▓čāą║ąŠą▓ąŠą╣ čüąĖą│ąĮą░ą╗, ą┐ąŠą┐ą░ą┤ą░čÄčé ą▓ ą║ą░ą┤čĆčŗ ą┐čĆąŠč鹊ą║ąŠą╗ą░ TCP/IP ą▓ ą▓ąĖą┤ąĄ ąŠčåąĖčäčĆąŠą▓ą░ąĮąĮčŗčģ ą▓čŗą▒ąŠčĆąŠą║ čüą┐ąĄą║čéčĆą░ čüąĖą│ąĮą░ą╗ą░, č鹊 ąĄčüčéčī čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠą│ąŠ ą║ąŠą┤ąĄą║ą░. ąóą░ą║ąŠą╣ ą┐ąŠą┤čģąŠą┤ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą░ą║čāčüčéąĖč湥čüą║ąĖą╣ čüąĖą│ąĮą░ą╗ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 300ŌĆō30 000 ąōčå ą▒ąĄąĘ ą┐ąŠč鹥čĆčī ąĄą│ąŠ čäčĆą░ą│ą╝ąĄąĮč鹊ą▓.
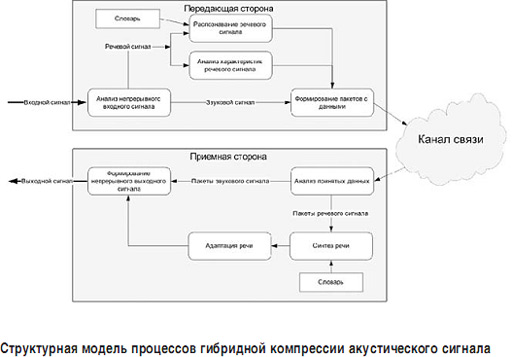
ąĪč乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą┐ą░ą║ąĄčéčŗ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ąĮą░ ą┐čĆąĖąĄą╝ąĮčāčÄ čüč鹊čĆąŠąĮčā ą┐ąŠ čüąĄčéąĖ ąśąĮč鹥čĆąĮąĄčé. ąØą░ ą┐čĆąĖąĄą╝ąĮąŠą╣ čüč鹊čĆąŠąĮąĄ čäčĆą░ą│ą╝ąĄąĮčéčŗ, ąĖąĘą▓ą╗ąĄč湥ąĮąĮčŗąĄ ąĖąĘ ą┐ą░ą║ąĄč鹊ą▓, ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčéčüčÅ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą░ąĮą░ą╗ąĖąĘą░ ą┐čĆąĖąĮčÅčéčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéąĖą┐ą░ (ąĘą▓čāą║ąŠą▓ąŠą╣ čüąĖą│ąĮą░ą╗ ąĖą╗ąĖ čĆąĄčćčī) ą╗ąĖą▒ąŠ čüąĖąĮč鹥ąĘąĖčĆčāčÄčéčüčÅ ą▓ čĆąĄčćčī, ą╗ąĖą▒ąŠ ą┤ąĄą║ąŠą┤ąĖčĆčāčÄčéčüčÅ ą▓ąŠ čäčĆą░ą│ą╝ąĄąĮčéčŗ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░. ąĪąĖąĮč鹥ąĘ čĆąĄčćąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ą┐čĆąŠčåąĄčüčü ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┤ą╗ąĖąĮąŠą╣ ąŠčé čüą╗ąŠą▓ą░ ą┤ąŠ č乊ąĮąĄą╝čŗ (čüą╗ąŠą│ą░) ą┐čāč鹥ą╝ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĪą£ą£ ą┐ąŠ ą║ąŠą┤čā ą┐ąŠą╗čāč湥ąĮąĮąŠą│ąŠ čüą╗ąŠą▓ą░ ąĖą╗ąĖ č乊ąĮąĄą╝čŗ. ąĪą£ą£ čü ąĮą░ąĖą▓čŗčüčłąĄą╣ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĮąŠą╣ ąŠčåąĄąĮą║ąŠą╣ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčéčüčÅ ą▓ čĆąĄčćčī. ą£ąĄčģą░ąĮąĖąĘą╝ ą░ą┤ą░ą┐čéą░čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┤ąŠą▒ąĖčéčīčüčÅ čüčģąŠąČąĄčüčéąĖ čüąĖąĮč鹥ąĘąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ, ą┐čĆąŠąĖąĘąĮąĄčüąĄąĮąĮąŠą│ąŠ ą┤ąĖą║č鹊čĆąŠą╝ čäčĆą░ą│ą╝ąĄąĮčéą░ ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░. ą¤čĆąŠčåąĄčüčü č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ čüąŠą▒ąĖčĆą░ąĄčé čäčĆą░ą│ą╝ąĄąĮčéčŗ čĆąĄč湥ą▓ąŠą│ąŠ ąĖ ąĘą▓čāą║ąŠą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ąŠą▓ ą▓ ąĄą┤ąĖąĮčŗą╣ ą▓čŗčģąŠą┤ąĮąŠą╣ čüąĖą│ąĮą░ą╗, ą║ąŠč鹊čĆčŗą╣ ąĘą░č鹥ą╝ ąĖ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ ąĮą░ ą┐čĆąĖąĄą╝ąĮąŠą╣ čüč鹊čĆąŠąĮąĄ.
ąÆčŗą┤ąĄą╗ąĖą╝ ą│ą╗ą░ą▓ąĮčŗąĄ ą┐čĆąŠčåąĄčüčüčŗ, ą▓ą╗ąĖčÅčÄčēąĖąĄ ąĮą░ ąĖą┤ąĄąĮčéąĖčćąĮąŠčüčéčī ą▓čģąŠą┤ąĮąŠą│ąŠ (ąĮą░ ą┐ąĄčĆąĄą┤ą░čÄčēąĄą╣ čüč鹊čĆąŠąĮąĄ) ąĖ ą▓čŗčģąŠą┤ąĮąŠą│ąŠ (ąĮą░ ą┐čĆąĖąĄą╝ąĮąŠą╣ čüč鹊čĆąŠąĮąĄ) ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░:
ą¤čĆąĄą┤ą╗ą░ą│ą░ąĄą╝čŗą╣ ąĮąŠą▓čŗą╣ ą┐ąŠą┤čģąŠą┤, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą▓ ą▓ąĖą┤ąĄ čüčéčĆčāą║čéčāčĆąĮąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ, čĆąĄčłą░čÄčēąĖą╣ ą┐čĆąŠą▒ą╗ąĄą╝čā ą▓čüąĄ ą▓ąŠąĘčĆą░čüčéą░čÄčēąĄą│ąŠ VoIP-čéčĆą░čäąĖą║ą░. ąŁč鹊 čüąĮąĖąČąĄąĮąĖąĄ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü č鹥čģąĮąŠą╗ąŠą│ąĖąĄą╣ VoIP ąŠą▒čŖąĄą╝ą░ ą┤ą░ąĮąĮčŗčģ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą▓ ą║ą░ąĮą░ą╗ čüą▓čÅąĘąĖ, ąĘą░ čüč湥čé ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą│ąĖą▒čĆąĖą┤ąĮąŠą╣ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ. ą¤čĆąĖ čŹč鹊ą╝ čĆąĄčćčī čüąĖąĮč鹥ąĘąĖčĆčāąĄčéčüčÅ čü čāč湥č鹊ą╝ č鹥ą╝ą▒čĆą░ą╗čīąĮčŗčģ ąĖ ą┐čüąĖčģąŠčŹą╝ąŠčåąĖąŠąĮą░ą╗čīąĮčŗčģ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ ą│ąŠą╗ąŠčüą░ ą┤ąĖą║č鹊čĆą░.
ąöą╗čÅ ąŠčåąĄąĮą║ąĖ čåąĄą╗ąĄčüąŠąŠą▒čĆą░ąĘąĮąŠčüčéąĖ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĮąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐čĆąŠą▓ąĄčüčéąĖ ą╝ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠčåąĄčüčüą░ ą░ąĮą░ą╗ąĖąĘą░ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą│ąŠ ą▓čģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ąĖ ą▓čŗčÅą▓ąĖčéčī ą┐čĆąŠčåąĄąĮčéąĮąŠąĄ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ ąĘą▓čāą║ą░ ąĖ čĆąĄčćąĖ ą▓ąŠ ą▓čģąŠą┤ąĮąŠą╝ ą░ą║čāčüčéąĖč湥čüą║ąŠą╝ čüąĖą│ąĮą░ą╗ąĄ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ č鹥ą╗ąĄč乊ąĮąĮąŠą│ąŠ čĆą░ąĘą│ąŠą▓ąŠčĆą░ ą░ą▒ąŠąĮąĄąĮč鹊ą▓ ąóążą×ą¤. ąóą░ą║ą░čÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą┐ąŠąĘą▓ąŠą╗ąĖčé čüą┐čĆąŠą│ąĮąŠąĘąĖčĆąŠą▓ą░čéčī ą║ąŠą╗ąĖč湥čüčéą▓ąĄąĮąĮčŗąĄ ąŠčåąĄąĮą║ąĖ čüč鹥ą┐ąĄąĮąĖ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, čéą░ą║ ą║ą░ą║ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé čüąČą░čéąĖčÅ ą║ą╗ą░čüčüąĖč湥čüą║ąĖčģ ą║ąŠą┤ąĄą║ąŠą▓ ąĖąĘą▓ąĄčüč鹥ąĮ, ą░ ą┐ąŠčĆčÅą┤ąŠą║ ą║ąŠą┤ąŠą▓ čĆą░čüą┐ąŠąĘąĮą░ąĮąĮąŠą│ąŠ čüą╗ąŠą▓ą░ ąĖą╗ąĖ č乊ąĮąĄą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čĆą░ąĘą╝ąĄčĆą░ą╝ąĖ čüą╗ąŠą▓ą░čĆčÅ. ą£ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠčåąĄčüčüą░ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ čĆąĄčćąĖ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓čŗčÅą▓ąĖčéčī ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗąĄ čĆą░ąĘą╝ąĄčĆčŗ čüą╗ąŠą▓ą░čĆčÅ ąĖ ą│ą╗čāą▒ąĖąĮčā ąĪą£ą£, ą░ čéą░ą║ąČąĄ ą▓čŗčÅą▓ąĖčé ą┐čĆąŠčåąĄąĮčé ąŠčłąĖą▒ąŠą║ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ čüą╗ąŠą▓ ąĖ č乊ąĮąĄą╝. ą£ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ čüąĖąĮč鹥ąĘą░ čĆąĄčćąĖ čü ą░ą┤ą░ą┐čéą░čåąĖąĄą╣ ą│ąŠą╗ąŠčüą░ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąŠčåąĄąĮąĖčéčī ą║ą░č湥čüčéą▓ąŠ čüąĖąĮč鹥ąĘąĖčĆčāąĄą╝ąŠą╣ čĆąĄčćąĖ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ąĖčüčģąŠą┤ąĮčŗą╝ ą│ąŠą╗ąŠčüąŠą╝ ą┤ąĖą║č鹊čĆą░. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ čüčéą░čéčīąĄ ą▒čŗą╗ą░ ąŠą┐ąĖčüą░ąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąŠ ąĄąĄ čĆąĄčłąĄąĮąĖąĄ ąĖ čüč乊čĆą╝čāą╗ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą░ą╗čīąĮąĄą╣čłąĖąĄ čłą░ą│ąĖ ą┐ąŠ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÄ ą┤ą░ąĮąĮąŠą╣ č鹥ą╝ą░čéąĖą║ąĖ.
ąøąĖč鹥čĆą░čéčāčĆą░:
ą×ą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ: ą¢čāčĆąĮą░ą╗ "ąóąĄčģąĮąŠą╗ąŠą│ąĖąĖ ąĖ čüčĆąĄą┤čüčéą▓ą░ čüą▓čÅąĘąĖ" #1, 2011
ą¤ąŠčüąĄčēąĄąĮąĖą╣: 5924
ąĪčéą░čéčīąĖ ą┐ąŠ č鹥ą╝ąĄ
ąÉą▓č鹊čĆ
| |||
ąÉą▓č鹊čĆ
| |||
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░č鹊čĆčüą║ąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣



