
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣

ąĀą░ąĘą▓ąĖčéąĖąĄ čüąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ č鹥čģąĮąŠą╗ąŠą│ąĖą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╗ąŠąČąĮčŗąĄ ą▒ąĖąŠą╝ąĄčéčĆąĖč湥čüą║ąĖąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą┤ą╗čÅ ą░čāč鹥ąĮčéąĖčäąĖą║ą░čåąĖąĖ ą╗ąĖčćąĮąŠčüčéąĖ ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┐čĆą░ą▓ ą┤ąŠčüčéčāą┐ą░ ą║ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅą╝. ąæąĖąŠą╝ąĄčéčĆąĖč湥čüą║ąĖąĄ ą░ą╗ą│ąŠčĆąĖčéą╝čŗ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą┤ą╗čÅ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ čüą║ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąŠčéą┐ąĄčćą░čéą║ąŠą▓ ą┐ą░ą╗čīčåąĄą▓, čĆą░ą┤čāąČąĮąŠą╣ ąŠą▒ąŠą╗ąŠčćą║ąĖ ąĖą╗ąĖ čüąĄčéčćą░čéą║ąĖ ą│ą╗ą░ąĘą░, ą│ąĄąŠą╝ąĄčéčĆąĖąĖ čĆčāą║; ą┤ą╗čÅ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą┐ąŠ ą╗ąĖčåčā; ą┤ą╗čÅ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ čĆąĄčćąĖ. ą¤čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠą╝ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ čĆąĄčćąĖ čÅą▓ą╗čÅąĄčéčüčÅ ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ čüą║ą░ąĮąĖčĆčāčÄčēąĄą│ąŠ ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮąĖčÅ. ąöą╗čÅ čüąĖčüč鹥ą╝, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą╝ą░čüčłčéą░ą▒ąĄ ą▓čĆąĄą╝ąĄąĮąĖ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ č鹊ą╗čīą║ąŠ ąĮą░ą╗ąĖčćąĖąĄ ą╝ąĖą║čĆąŠč乊ąĮą░ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ čĆąĄčćąĖ. ąóąĄčģąĮąŠą╗ąŠą│ąĖčÅ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąĮąĄą▓čŗčüąŠą║ąŠą╣ čüč鹊ąĖą╝ąŠčüčéčīčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ, ą┐čĆąĖ čŹč鹊ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ.
ąĀąĄčćčī čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąŠą╣ ąĖąĘ č乊čĆą╝ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ čÅąĘčŗą║ą░ ąĖ čüąŠą┤ąĄčƹȹĖčé ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ čüą▓ąŠąĄą╝ ąĖčüč鹊čćąĮąĖą║ąĄ. ą×ąĮą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą╗ č湥ą╗ąŠą▓ąĄą║ą░, čüčāą┤ąĖčéčī ąŠ ąĄą│ąŠ ąĘą┤ąŠčĆąŠą▓čīąĄ ąĖ 菹╝ąŠčåąĖąŠąĮą░ą╗čīąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ. ąĀąĄčćčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░ ą┤ą╗čÅ ąŠą▒čēąĄąĮąĖčÅ, čé.ąĄ. ą║ąŠą╝ą╝čāąĮąĖą║ą░čåąĖąĖ ą╝ąĄąČą┤čā ąŠą▒čŖąĄą║čéą░ą╝ąĖ (ą╗čÄą┤čīą╝ąĖ ąĖą╗ąĖ čüąĖčüč鹥ą╝ą░ą╝ąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆąĄčćąĖ), ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą║ąŠč鹊čĆąŠą╣ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒ą╝ąĄąĮ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣. ąĀąĄčćčī ą╝ąŠąČąĮąŠ ąŠą┐ąĖčüą░čéčī ą║ą░ą║ ąĄąĄ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗą╝ čüąŠą┤ąĄčƹȹ░ąĮąĖąĄą╝, čéą░ą║ ąĖ ą▓ ą▓ąĖą┤ąĄ čüąĖą│ąĮą░ą╗ą░, čé.ąĄ. ą░ą║čāčüčéąĖč湥čüą║ąŠą│ąŠ ą║ąŠą╗ąĄą▒ą░ąĮąĖčÅ. ą×ą▒čĆą░ą▒ąŠčéą║čā čéą░ą║ąŠą│ąŠ ą▓ąĖą┤ą░ čüąĖą│ąĮą░ą╗ąŠą▓ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčé č鹥ąŠčĆąĖčÅ čåąĖčäčĆąŠą▓ąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆąĄč湥ą▓čŗčģ čüąĖą│ąĮą░ą╗ąŠą▓ [1]. ąóąĄąŠčĆąĖčÅ ą┐ąŠą┤čĆą░ąĘą┤ąĄą╗čÅąĄčé ą▓čüąĄ čüąĖčüč鹥ą╝čŗ čĆąĄč湥ą▓ąŠą│ąŠ ąŠą▒ą╝ąĄąĮą░ ą╝ąĄąČą┤čā č湥ą╗ąŠą▓ąĄą║ąŠą╝ ąĖ ą╝ą░čłąĖąĮąŠą╣ (ą▓ čüą╗čāčćą░ąĄ IoT ą▓ ą║ą░č湥čüčéą▓ąĄ ą╝ą░čłąĖąĮčŗ ą▓čŗčüčéčāą┐ą░ąĄčé ąŠą▒čŖąĄą║čé ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ąśąĮč鹥čĆąĮąĄčéą░ ą▓ąĄčēąĄą╣) ąĮą░ čéčĆąĖ ą║ą╗ą░čüčüą░: čü čĆąĄč湥ą▓čŗą╝ ąŠčéą▓ąĄč鹊ą╝, čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖąĄą╝ ą┤ąĖą║č鹊čĆą░ ąĖ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖąĄą╝ čĆąĄčćąĖ. ąæąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüąĖčüč鹥ą╝čŗ ą▓č鹊čĆąŠą│ąŠ ą║ą╗ą░čüčüą░, ą║ąŠč鹊čĆčŗąĄ, ą▓ čüą▓ąŠčÄ ąŠč湥čĆąĄą┤čī, čĆą░čüą┐ą░ą┤ą░čÄčéčüčÅ ąĮą░ ą┤ą▓ą░ ą┐ąŠą┤ą║ą╗ą░čüčüą░: čüąĖčüč鹥ą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░.
ąÆąĄčĆąĖčäąĖą║ą░čåąĖčÅ čĆąĄčćąĖ ŌĆō ą┐čĆąŠčåąĄčüčü čĆąĄčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ąŠ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĮąŠčüčéąĖ ą┤ąĖą║č鹊čĆą░ ą║ ąĮąĄą║ąŠč鹊čĆąŠą╣ ą│čĆčāą┐ą┐ąĄ ą╗ąĖčå. ąÆ ą┐čĆąŠčåąĄčüčüąĄ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆčā čéčĆąĄą▒čāąĄčéčüčÅ ą▓ą▓ąĄčüčéąĖ ą▓ čüąĖčüč鹥ą╝čā čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ, ą┐ąŠą┤čéą▓ąĄčƹȹ┤ą░čÄčēąĖąĄ ąĄą│ąŠ ą┐čĆą░ą▓ąŠ ąĮą░ ą░čāč鹥ąĮčéąĖčäąĖą║ą░čåąĖčÄ, ą░ ąĘą░č鹥ą╝ ą┐čĆąŠąĖąĘąĮąĄčüčéąĖ čŹčéą░ą╗ąŠąĮąĮčāčÄ čäčĆą░ąĘčā. ąĪąĖčüč鹥ą╝ą░ ąŠą▒čĆą░ą▒ąŠčéą░ąĄčé ą┐čĆąŠąĖąĘąĮąĄčüąĄąĮąĮčāčÄ čäčĆą░ąĘčā ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, čüčĆą░ą▓ąĮąĖčé ąĖčģ čü čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ą░ą╝ąĖ čŹčéą░ą╗ąŠąĮą░, ą┤ą░ąĮąĮčŗąĄ ą║ąŠč鹊čĆąŠą│ąŠ ą▒čŗą╗ąĖ čāą║ą░ąĘą░ąĮčŗ ą┤ąĖą║č鹊čĆąŠą╝, ą┐ąŠčüčéčĆąŠąĖčé ą╝ą░čéčĆąĖčåčā ą┐ąŠč鹥čĆčī cl (1), ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčēčāčÄ ą┐ąŠą╗ąĮčāčÄ ąŠčłąĖą▒ą║čā, ąĖ ą▓čŗąĮąĄčüąĄčé čĆąĄčłąĄąĮąĖąĄ ąŠą▒ ąĖą┤ąĄąĮčéąĖčćąĮąŠčüčéąĖ ą┤ąĖą║č鹊čĆą░ ąĘą░čÅą▓ą╗ąĄąĮąĮąŠą╝čā ą╗ąĖčåčā. ą¤čĆąĖ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąŠą┤ąĮąŠą║čĆą░čéąĮąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ąĖąĘą╝ąĄčĆąĄąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ čŹčéą░ą╗ąŠąĮą░, ąĮą░ ąŠčüąĮąŠą▓ąĄ ą║ąŠč鹊čĆąŠą│ąŠ ąĖ ą┐čĆąĖąĮąĖą╝ą░ąĄčéčüčÅ čĆąĄčłąĄąĮąĖąĄ ąŠą▒ ąĖą┤ąĄąĮčéąĖčćąĮąŠčüčéąĖ ą┤ąĖą║č鹊čĆą░. ąĀąĄčłąĄąĮąĖąĄ ąŠą▒ čāą┤ą░čćąĮąŠą╣ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┐čĆąĖąĮąĖą╝ą░ąĄčéčüčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą┐čĆą░ą▓ąĖą╗ą░ ą▓ąĖą┤ą░:
ąÆąĄčĆąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą┤ąĖą║č鹊čĆą░ l, ąĄčüą╗ąĖ

ą×čéą║ą╗ąŠąĮąĖčéčī ą┤ąĖą║č鹊čĆą░ l, ąĄčüą╗ąĖ
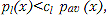
ą│ą┤ąĄ clŌĆō ą║ąŠąĮčüčéą░ąĮčéą░ ą┤ą╗čÅ l-ą│ąŠ ą┤ąĖą║č鹊čĆą░, ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčēą░čÅ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĖ ąŠčłąĖą▒ąŠą║ l-ą│ąŠ ą┤ąĖą║č鹊čĆą░, pω (x) ŌĆō čüčĆąĄą┤ąĮąĄąĄ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĖ (ą┐ąŠ ą▓čüąĄą╝čā ąĮą░ą▒ąŠčĆčā ą┤ąĖą║č鹊čĆąŠą▓) ąĖąĘą╝ąĄčĆąĄąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą▓ąĄą║č鹊čĆą░ x. ąśąĘą╝ąĄąĮčÅčÅ ą┐ąŠčĆąŠą│cl, ą╝ąŠąČąĮąŠ ąĖąĘą╝ąĄąĮąĖčéčī ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī ąŠčłąĖą▒ą║ąĖ, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝čāčÄ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčÅą╝ąĖ ą╗ąŠąČąĮąŠą╣ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ąĖą╗ąĖ ąŠčéą║ą░ąĘą░ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┐ąŠą┤ą╗ąĖąĮąĮąŠą│ąŠ ą┤ąĖą║č鹊čĆą░.
ąśą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖčÅ čĆąĄčćąĖ ŌĆō čŹč鹊 ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┤ąĖą║č鹊čĆą░ ąĖąĘ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ąĖąĘą▓ąĄčüčéąĮąŠą│ąŠ ą╝ąĮąŠąČąĄčüčéą▓ą░. ąĢąĄ ąĘą░ą┤ą░čćą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ č鹊čćąĮąŠ čāą║ą░ąĘą░čéčī ąŠą┤ąĮąŠą│ąŠ ąĖąĘ ą┤ąĖą║č鹊čĆąŠą▓ čüčĆąĄą┤ąĖ N ą┤ąĖą║č鹊čĆąŠą▓ ą╝ąĮąŠąČąĄčüčéą▓ą░. ą¤ąŠčŹč鹊ą╝čā ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą▓ą╝ąĄčüč鹊 ąŠą┤ąĮąŠą║čĆą░čéąĮąŠą│ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĖąĘą╝ąĄčĆąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čü čģčĆą░ąĮčÅčēąĖą╝ąĖčüčÅ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ ą▓ ą▓ąĖą┤ąĄ čŹčéą░ą╗ąŠąĮą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐čĆąŠą▓ąĄčüčéąĖ N čüčĆą░ą▓ąĮąĄąĮąĖą╣. ą¤čĆą░ą▓ąĖą╗ąŠ ą┐čĆąĖąĮčÅčéąĖčÅ čĆąĄčłąĄąĮąĖčÅ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čüą▓ąŠą┤ąĖčéčüčÅ ą║ ą▓čŗą▒ąŠčĆčā čéą░ą║ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ l, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ
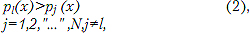
čé.ąĄ. ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą┤ąĖą║č鹊čĆ čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╣ ą░ą▒čüąŠą╗čÄčéąĮąŠą╣ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčīčÄ ąŠčłąĖą▒ą║ąĖ. ą¤čĆąĖ čŹč鹊ą╝ čü čāą▓ąĄą╗ąĖč湥ąĮąĖąĄą╝ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┤ąĖą║č鹊čĆąŠą▓ ą▓ąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄ ą▓ąŠąĘčĆą░čüčéą░ąĄčé ąĖ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī ąŠčłąĖą▒ą║ąĖ, čé.ą║. ą▒ąŠą╗čīčłąŠąĄ čćąĖčüą╗ąŠ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĮčŗčģ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖą╣ ą▓ ąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąĮąĄ ą╝ąŠąČąĄčé ąĮąĄ ą┐ąĄčĆąĄčüąĄą║ą░čéčīčüčÅ. ąæąŠą╗ąĄąĄ ą▓ąĄčĆąŠčÅčéąĮčŗą╝ čüčéą░ąĮąŠą▓ąĖčéčüčÅ č鹊čé čäą░ą║čé, čćč鹊 ą┤ą▓ą░ ąĖą╗ąĖ ą▒ąŠą╗ąĄąĄ ą┤ąĖą║č鹊čĆąŠą▓ ą▓ ąŠą▒čēąĄą╝ ą╝ąĮąŠąČąĄčüčéą▓ąĄ ą▒čāą┤čāčé ąĖą╝ąĄčéčī čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą▓ąĄčĆąŠčÅčéąĮąŠčüč鹥ą╣ ą▒ą╗ąĖąĘą║ąĖą╝ ą┤čĆčāą│ ą║ ą┤čĆčāą│čā. ąÆčüąĄ čŹč鹊 ąĮąĄą│ą░čéąĖą▓ąĮąŠ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą║ą░č湥čüčéą▓ąŠ ą┐čĆąĖąĮčÅčéąĖčÅ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░.
ąŚą░ą┤ą░čćąĖ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čĆąĄčćąĖ čÅą▓ą╗čÅčÄčéčüčÅ ą┐ąŠ čüą▓ąŠąĄą╣ čüčāčéąĖ čüčģąŠą┤ąĮčŗą╝ąĖ, ąĮąŠ ą▓ č鹊 ąČąĄ ą▓čĆąĄą╝čÅ ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé ąĖ čĆą░ąĘą╗ąĖčćąĖčÅ. ąÆ ą║ą░ąČą┤ąŠą╝ čüą╗čāčćą░ąĄ ą┤ąĖą║č鹊čĆ ą┤ąŠą╗ąČąĄąĮ ą┐čĆąŠąĖąĘąĮąĄčüčéąĖ č鹥čüč鹊ą▓čāčÄ čäčĆą░ąĘčā. ąÆ ą┐čĆąŠčåąĄčüčüąĄ ą░ąĮą░ą╗ąĖąĘą░ čäčĆą░ąĘčŗ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčéčüčÅ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ, ą░ ąĘą░č鹥ą╝ ą▓čŗčćąĖčüą╗čÅčÄčéčüčÅ ąŠą┤ąĮą░ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĄčĆ čĆą░ąĘą╗ąĖčćąĖą╝ąŠčüčéąĖ ą╝ąĄąČą┤čā č鹥ą║čāčēąĖą╝ąĖ ąĖ čŹčéą░ą╗ąŠąĮąĮčŗą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ. ąØą░ čŹč鹊ą╝ čłą░ą│ąĄ čü ą┐ąŠąĘąĖčåąĖąĖ čåąĖčäčĆąŠą▓ąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠą▒ąĄ ąĘą░ą┤ą░čćąĖ čüčģąŠą┤ąĮčŗ. ą×čüąĮąŠą▓ąĮąŠąĄ ąČąĄ čĆą░ąĘą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĮą░ čŹčéą░ą┐ąĄ ą▓čŗąĮąĄčüąĄąĮąĖčÅ čĆąĄčłąĄąĮąĖą╣, ą│ą┤ąĄ ą▓ čüą╗čāčćą░ąĄ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĘą░ą┤ą░čćčā ą▒ąĖąĮą░čĆąĮąŠą│ąŠ ą▓čŗą▒ąŠčĆą░, čé.ąĄ. ą┐čĆąĖąĮčÅčéčī ąĖą╗ąĖ ąŠčéą║ą╗ąŠąĮąĖčéčī čāčéą▓ąĄčƹȹ┤ąĄąĮąĖąĄ, čćč鹊 ą│ąŠą╗ąŠčü ą▓ąĄčĆąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ ąĖą┤ąĄąĮčéąĖč湥ąĮ čŹčéą░ą╗ąŠąĮčā. ąöą╗čÅ čŹč鹊ą│ąŠ ą┤ąŠčüčéą░č鹊čćąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąŠčĆą╝ąĖčĆąŠą▓ą░ąĮąĮąŠą╣ čüčāą╝ą╝čŗ ą║ą▓ą░ą┤čĆą░č鹊ą▓
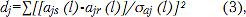
ą│ą┤ąĄ ajs (l) ŌĆō ąĘąĮą░č湥ąĮąĖąĄ j-ą╣ čéčĆą░ąĄą║č鹊čĆąĖąĖ ą▓čģąŠą┤ąĮąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą▓ ą╝ąŠą╝ąĄąĮčé l; ajr (l) ŌĆō ąĘąĮą░č湥ąĮąĖąĄ j-ą╣ čéčĆą░ąĄą║č鹊čĆąĖąĖ čŹčéą░ą╗ąŠąĮą░ ą▓ ą╝ąŠą╝ąĄąĮčé l; σaj (l)ŌĆō čüčéą░ąĮą┤ą░čĆčéąĮąŠąĄ ąŠčéą║ą╗ąŠąĮąĄąĮąĖąĄ j-ą╣ čéčĆą░ąĄą║č鹊čĆąĖąĖ ą▓ ą╝ąŠą╝ąĄąĮčé l. ą¤ąŠą╗ąĮą░čÅ ąČąĄ ą╝ąĄčĆą░ čĆą░ąĘą╗ąĖčćąĖą╝ąŠčüčéąĖ ą╝ąŠąČąĄčé ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčéčī čüąŠą▒ąŠą╣ ą▓ąĘą▓ąĄčłąĄąĮąĮčāčÄ čüčāą╝ą╝čā ą║ąŠčĆąĮąĄą╣

ą│ą┤ąĄ ωj ŌĆō ą▓ąĄčü, ą▓čŗą▒ąĖčĆą░ąĄą╝čŗą╣ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ j-ą│ąŠ ąĖąĘą╝ąĄčĆąĄąĮąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čéčĆą░ąĄą║č鹊čĆąĖąĖ ą▓ąĄčĆąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░.
ąÆ čüą╗čāčćą░ąĄ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čĆąĄčćąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ (4) ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ ą╝ąĄčĆ čĆą░ąĘą╗ąĖčćąĖą╝ąŠčüčéąĖ, ąŠčüąĮąŠą▓ą░ąĮąĮčŗčģ ąĮą░ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĮčŗčģ ą╝ąŠą┤ąĄą╗čÅčģ. ąÜą╗ą░čüčüąĖč湥čüą║ąĖą╝ąĖ ą┐čĆąĖą╝ąĄčĆą░ą╝ąĖ čéą░ą║ąĖčģ ą╝ąŠą┤ąĄą╗ąĄą╣ čÅą▓ą╗čÅčÄčéčüčÅ čüą║čĆčŗčéą░čÅ ą╝ą░čĆą║ąŠą▓čüą║ą░čÅ ą╝ąŠą┤ąĄą╗čī (ąĪą£ą£/HMM) ąĖ ą╝ąŠą┤ąĄą╗čī čüą╝ąĄčüąĖ ąĮąŠčĆą╝ą░ą╗čīąĮčŗčģ ą│ą░čāčüčüąŠą▓čŗčģ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖą╣ (ąĪąōąĀ/GMM). ąĪą£ą£ ŌĆō čŹč鹊 čüčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą╝ąĄč鹊ą┤, ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░čÄčēąĖą╣, čćč鹊 ą╝ąŠą┤ąĄą╗čī čüąĖčüč鹥ą╝čŗ ąĄčüčéčī ą╝ą░čĆą║ąŠą▓čüą║ąĖą╣ ą┐čĆąŠčåąĄčüčü čü ąĮąĄąĖąĘą▓ąĄčüčéąĮčŗą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ. ą”ąĄą╗čīčÄ ą╝ąĄč鹊ą┤ą░ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄąĖąĘą▓ąĄčüčéąĮčŗčģ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čåąĄą┐ąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĮą░ą▒ą╗čÄą┤ą░ąĄą╝čŗčģ. ąĪąōąĀ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąĖč湥čüą║ąŠą╣ čäčāąĮą║čåąĖąĄą╣ ą┐ą╗ąŠčéąĮąŠčüčéąĖ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĖ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮąŠą╣ ą║ą░ą║ ą▓ąĘą▓ąĄčłąĄąĮąĮą░čÅ čüčāą╝ą╝ą░ čäčāąĮą║čåąĖą╣ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ (ą│ą░čāčüčüąŠą▓čüą║ąĖčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé). ąØąĄą╣čĆąŠąĮąĮčŗąĄ čüąĄčéąĖ ąĖ ą╝ąĄč鹊ą┤ ąŠą┐ąŠčĆąĮčŗčģ ą▓ąĄą║č鹊čĆąŠą▓ (SVM) čéą░ą║ąČąĄ ąĮą░čłą╗ąĖ čüą▓ąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ą▓ čüč乥čĆąĄ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čĆąĄčćąĖ, ąĮąŠ ą░ą║čéąĖą▓ąĮą░čÅ ąĖčüčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ ą┤ąĄčÅč鹥ą╗čīąĮąŠčüčéčī ą▓ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ ąĄčēąĄ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ.
ąĪąŠą│ą╗ą░čüąĮąŠ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÄ [2] ą┤ą╗čÅ č鹥ą║čüč鹊ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ čüąĖčüč鹥ą╝ ą╝ąŠą┤ąĄą╗ąĖ ąĪąōąĀ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čüąŠ ąĪą£ą£, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╝ ą╗čāčćčłąĖą╣ čĆąĄąĘčāą╗čīčéą░čé ą┤ą╗čÅ čüąĖčüč鹥ą╝, ą│ą┤ąĄ ą┐čĆąŠąĖąĘąĮąŠčüąĖą╝čŗą╣ ą┤ąĖą║č鹊čĆąŠą╝ č鹥ą║čüčé ąĖąĘą▓ąĄčüč鹥ąĮ ąĘą░čĆą░ąĮąĄąĄ. ą¤ąŠčŹč鹊ą╝čā ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ čüąĖčüč鹥ą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ/ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĖą╝ąĄąĮąĮąŠ ą╝ąŠą┤ąĄą╗ąĖ ąĪąōąĀ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ čéą░ą║ąŠą╣ čĆą░ą▒ąŠčéą░čÄčēąĄą╣ čüąĖčüč鹥ą╝čŗ ą╝ąŠąČąĮąŠ ą┐čĆąĖą▓ąĄčüčéąĖ ą┐čĆąŠąĄą║čé ALIZE [3]. ALIZE ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ąŠčéą║čĆčŗčéčāčÄ ą┐ą╗ą░čéč乊čĆą╝čā ą▒ąĖąŠą╝ąĄčéčĆąĖč湥čüą║ąŠą╣ ą░čāč鹥ąĮčéąĖčäąĖą║ą░čåąĖąĖ, čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮčāčÄ ąĮą░ čÅąĘčŗą║ąĄ ąĪąĖ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ąĖ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ čĆąĄčćąĖ. ą¤ą╗ą░čéč乊čĆą╝ą░ čüąŠą┤ąĄčƹȹĖčé ą▓čüąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆąĄčćąĖ ąĖ čĆą░ą▒ąŠčéčŗ čü ą╝ąŠą┤ąĄą╗čīčÄ ąĪąōąĀ.
ąÆ ąŠą▒čēąĄą╝ ą▓ąĖą┤ąĄ ą┐čĆąŠčåąĄčüčü ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą╝ąŠą┤ąĄą╗ąĖ ąĪąōąĀ ą╝ąŠąČąĮąŠ ąŠą┐ąĖčüą░čéčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ čüą╗ąĄą┤čāčÄčēąĖčģ čłą░ą│ąŠą▓:
1. ąśąĘą▓ą╗ąĄč湥ąĮąĖąĄ ąĖąĘ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗčģ ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣ ą│ąŠą╗ąŠčüą░ č湥ą╗ąŠą▓ąĄą║ą░ (ą┐čĆąĖąĘąĮą░ą║ąŠą▓). ąØą░ čŹč鹊ą╝ čłą░ą│ąĄ čäčĆą░ą│ą╝ąĄąĮčéčŗ čĆąĄčćąĖ ą┐čĆąĄąŠą▒čĆą░ąĘčāčÄčéčüčÅ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓ąĄą║č鹊čĆą░, ą░ ą▓ąĄčüčī čĆąĄč湥ą▓ąŠą╣ čüąĖą│ąĮą░ą╗ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ čŹčéąĖčģ ą▓ąĄą║č鹊čĆąŠą▓.
2. ąĪąŠąĘą┤ą░ąĮąĖąĄ čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮąŠą╣ č乊ąĮąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ (ąŻążą£/UBM). ąŻążą£ ąŠą┐ąĖčüčŗą▓ą░ąĄčé čāčüčĆąĄą┤ąĮąĄąĮąĮčŗąĄ ą│ąŠą╗ąŠčüąŠą▓čŗąĄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ ą▓čüąĄčģ ą┤ąĖą║č鹊čĆąŠą▓ ąĖąĘą▓ąĄčüčéąĮąŠą│ąŠ ą╝ąĮąŠąČąĄčüčéą▓ą░. ąÆ ą┤ą░ą╗čīąĮąĄą╣čłąĄą╝ ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ čŹč鹊ą╣ ą╝ąŠą┤ąĄą╗ąĖ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ čüč鹥ą┐ąĄąĮčī čāąĮąĖą║ą░ą╗čīąĮąŠčüčéąĖ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗąĮąĄčüąĄąĮąĖčÅ čĆąĄčłąĄąĮąĖčÅ ąŠą▒ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ąĖą╗ąĖ ąĄą│ąŠ ąŠčéą║ą╗ąŠąĮąĄąĮąĖąĖ. ąŻążą£ čüąŠąĘą┤ą░ąĄčéčüčÅ ąĮą░ čŹčéą░ą┐ąĄ ąŠą▒čāč湥ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ.
3. ąĪąŠąĘą┤ą░ąĮąĖąĄ ą╝ąŠą┤ąĄą╗ąĖ ąĪąōąĀ (ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ) ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ ą▓ąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄ. ąØą░ čŹč鹊ą╝ čłą░ą│ąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ąŻążą£ ą▓ čüąŠč湥čéą░ąĮąĖąĖ čü ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ ą▓ąĄą║č鹊čĆąŠą▓ ą│ąŠą╗ąŠčüąŠą▓čŗčģ ą┐čĆąĖąĘąĮą░ą║ąŠą▓ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ ąĖąĘ ą╝ąĮąŠąČąĄčüčéą▓ą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╝ąĄč鹊ą┤ą░ ą░ą┐ąŠčüč鹥čĆąĖąŠčĆąĮąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░ (MAP) [4]. ąōąŠą╗ąŠčüąŠą▓čŗąĄ ą╝ąŠą┤ąĄą╗ąĖ čüąŠąĘą┤ą░čÄčéčüčÅ ąĮą░ čŹčéą░ą┐ąĄ ąŠą▒čāč湥ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ.
4. ą×čåąĄąĮą║ą░ ą┐ąŠą╗čāč湥ąĮąĮčŗčģ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓čģąŠą┤ąĮąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┐čĆąĖąĘąĮą░ą║ąŠą▓ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ ą▓ąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄ.
5. ą¤čĆąĖąĮčÅčéąĖąĄ čĆąĄčłąĄąĮąĖčÅ ąŠą▒ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą│ąŠ ą▓ čüąĖčüč鹥ą╝ąĄ ą┐ąŠčĆąŠą│ą░ ąĖ ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ ąŠčåąĄąĮą║ąĖ ą║ą░ąČą┤ąŠą╣ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ.
ąĪą╗ąĄą┤čāąĄčé ąŠčéą╝ąĄčéąĖčéčī, čćč鹊 čüąĖčüč鹥ą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ/ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ čĆą░ą▒ąŠčéą░čÄčé ą▓ ą┤ą▓čāčģ čĆąĄąČąĖą╝ą░čģ. ą¤ąĄčĆą▓čŗą╣ čĆąĄąČąĖą╝ ŌĆō ąŠą▒čāč湥ąĮąĖčÅ, ąĖą╗ąĖ čĆąĄąČąĖą╝ čüąŠąĘą┤ą░ąĮąĖčÅ čŹčéą░ą╗ąŠąĮąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣, ą║ąŠą│ą┤ą░ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĮą░ą▒ąŠčĆą░ ąĘą▓čāą║ąŠą▓čŗčģ ąĘą░ą┐ąĖčüąĄą╣ ą┤ąĖą║č鹊čĆąŠą▓ (wav, raw ąĖ čé.ą┤.) čüąŠąĘą┤ą░ąĄčéčüčÅ ąŻążą£, ą░ ąĘą░č鹥ą╝ ą│ąŠą╗ąŠčüąŠą▓ą░čÅ ą╝ąŠą┤ąĄą╗čī ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░ (čłą░ą│ąĖ 1ŌĆō2ŌĆō3). ąÆč鹊čĆąŠą╣ čĆąĄąČąĖą╝ ŌĆō čĆą░ą▒ąŠčćąĖą╣, ą║ąŠą│ą┤ą░ ąĖąĘ ą▓ąĄčĆąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ/ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ ą┐čĆąĖąĘąĮą░ą║ąĖ, ą░ ąĘą░č鹥ą╝ ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ čŹčéąĖčģ ą┐čĆąĖąĘąĮą░ą║ąŠą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ ą┐ąŠąĖčüą║ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą▓ ąĮą░ą▒ąŠčĆąĄ čŹčéą░ą╗ąŠąĮąŠą▓ (ąĖą╗ąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čü čāą║ą░ąĘą░ąĮąĮąŠą╣ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗čīčÄ ą▓ čüą╗čāčćą░ąĄ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ) ąĖ ą┐čĆąĖąĮąĖą╝ą░ąĄčéčüčÅ čĆąĄčłąĄąĮąĖąĄ ąŠ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ/ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ąĖą╗ąĖ ąĄą│ąŠ ąŠčéą║ą╗ąŠąĮąĄąĮąĖąĖ (čłą░ą│ąĖ 1ŌĆō4ŌĆō5).
ąöą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą╝ąŠą┤ąĄą╗ąĖ čüąĖčüč鹥ą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ/ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ ą▒čŗą╗ ą▓čŗą▒čĆą░ąĮ, ą║ą░ą║ ąŠčéą╝ąĄčćą░ą╗ąŠčüčī čĆą░ąĮąĄąĄ, ąŠčéą║čĆčŗčéčŗą╣ ą┐čĆąŠąĄą║čé ALIZE. ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ąŠą┤ąĮąŠą┐ą╗ą░čéąĮčŗą╣ ą║ąŠą╝ą┐čīčÄč鹥čĆ čü 4-čÅą┤ąĄčĆąĮčŗą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ARM Cortex-A7 900 ą£ąōčå ąĖ 1 ąōą▒ą░ą╣čé ą×ąŚąŻ, ąĮą░ ą║ąŠč鹊čĆąŠą╝ ą▒čŗą╗ąŠ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠąĄ ą┤ą╗čÅ čüą▒ąŠčĆą║ąĖ ąĪąĖ-ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ. ą¤ą╗ą░čéč乊čĆą╝ą░ ALIZE ą▓ąĄčĆčüąĖąĖ 3.0, čüąŠčüč鹊čÅčēą░čÅ ąĖąĘ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ALIZE ąĖ ąĮą░ą▒ąŠčĆą░ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ą╗čīąĮčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ LIA_RAL, ą▒čŗą╗ą░ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ąĖ čüąŠą▒čĆą░ąĮą░ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ. ą¤čĆąĖąĘąĮą░ą║ąĖ čĆąĄčćąĖ ąĖąĘą▓ą╗ąĄą║ą░ą╗ąĖčüčī čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆąĄčćąĖ SPro [5] ą▓ąĄčĆčüąĖąĖ 4.0.1. ąöą╗čÅ ąŠą▒čāč湥ąĮąĖčÅ ąĖ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī čäčĆą░ą│ą╝ąĄąĮčéčŗ čĆąĄčćąĖ ą░ą║č鹥čĆąŠą▓ ąĖąĘ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą║ąĖąĮąŠčäąĖą╗čīą╝ąŠą▓. ą¤ąŠ ą╝ąĮąĄąĮąĖčÄ ą░ą▓č鹊čĆą░, ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ čŹčéą░ą╗ąŠąĮąĮčŗąĄ ą│ąŠą╗ąŠčüąŠą▓čŗąĄ ą╝ąŠą┤ąĄą╗ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐ąŠą┤ąŠą▒ąĮčŗ ą╝ąŠą┤ąĄą╗čÅą╝, čüąŠąĘą┤ą░ąĮąĮčŗą╝ ą▓ čĆąĄą░ą╗čīąĮčŗčģ, ą░ ąĮąĄ čüčéčāą┤ąĖą╣ąĮčŗčģ čāčüą╗ąŠą▓ąĖčÅčģ, ąĖ čüąŠą┤ąĄčƹȹ░čé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ąĄčüč鹥čüčéą▓ąĄąĮąĮčŗąĄ čłčāą╝čŗ.
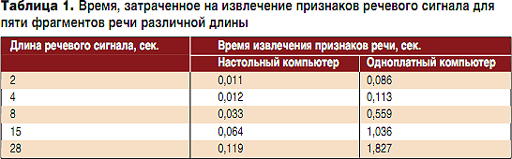
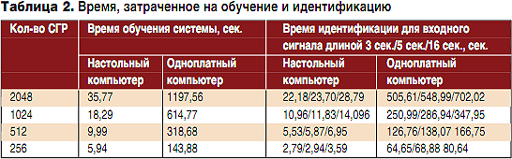
ąöą╗čÅ ąŠčåąĄąĮą║ąĖ čüąŠąĘą┤ą░ąĮąĮąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ čüąĖčüč鹥ą╝čŗ ą▓čüąĄ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ ą┐čĆąŠą▓ąŠą┤ąĖą╗ąĖčüčī ą║ą░ą║ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ, čéą░ą║ ąĖ ąĮą░ ąĮą░čüč鹊ą╗čīąĮąŠą╝ ą║ąŠą╝ą┐čīčÄč鹥čĆąĄ (Intel Core i7-4770K CPU @ 3.50 ąōąōčå, 16 ąōą▒ą░ą╣čé ą×ąŚąŻ, Ubuntu 13.10 64-bit) čü čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╣ ą┐ą╗ą░čéč乊čĆą╝ąŠą╣ ALIZE ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ ą┤ą╗čÅ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗčģ čĆąĄč湥ą▓čŗčģ čäčĆą░ą│ą╝ąĄąĮč鹊ą▓. ąÆ čéą░ą▒ą╗ąĖčåąĄ 1 ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ ąĮą░ ąĖąĘą▓ą╗ąĄč湥ąĮąĖąĄ ą┐čĆąĖąĘąĮą░ą║ąŠą▓ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ (60 ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąĮą░ ąŠą┤ąĖąĮ ą▓ąĄą║č鹊čĆ) ą┤ą╗čÅ ą┐čÅčéąĖ čäčĆą░ą│ą╝ąĄąĮč鹊ą▓ čĆąĄčćąĖ čĆą░ąĘą╗ąĖčćąĮąŠą╣ ą┤ą╗ąĖąĮčŗ.
ąÆ čéą░ą▒ą╗ąĖčåąĄ 2 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąŠ ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ ąĮą░ ąŠą▒čāč湥ąĮąĖąĄ (ą│ąĄąĮąĄčĆą░čåąĖčÄ ąŻążą£ ąĖ ą│ąŠą╗ąŠčüąŠą▓čŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĖą║č鹊čĆą░) ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖčÄ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĪąōąĀ ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ čü ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ąĖąĘ ą┤ąĄčüčÅčéąĖ ą┤ąĖą║č鹊čĆąŠą▓.
ąØą░ čĆąĖčüčāąĮą║ąĄ ąĖąĘąŠą▒čĆą░ąČąĄąĮ ą┐čĆąŠčåąĄąĮčé ąŠčłąĖą▒ąŠą║ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ (ą╗ąŠąČąĮą░čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖčÅ ąĖ ąŠčéą║ą░ąĘ ą▓ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ) ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĪąōąĀ ą▓ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┤ąĖą║č鹊čĆą░ ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ čü ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ąĖąĘ ą┤ąĄčüčÅčéąĖ ą┤ąĖą║č鹊čĆąŠą▓ ą┐čĆąĖ ąĮąĄąĖąĘą╝ąĄąĮąĮąŠą╝ ą┐ąŠčĆąŠą│ąŠą▓ąŠą╝ ąĘąĮą░č湥ąĮąĖąĖ, čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╝ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ą£ąŠą┤ąĄą╗čī ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ čüąĖčüč鹥ą╝čŗ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ/ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čÅą▓ą╗čÅąĄčéčüčÅ č鹥ą║čüč鹊ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠą╣. ą¤ąŠčŹč鹊ą╝čā ą▓ ą║ą░č湥čüčéą▓ąĄ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čĆąĄčćčī ą┤ąĖą║č鹊čĆą░, ą┐čĆąĖčüčāčéčüčéą▓čāčÄčēąĄą│ąŠ ą▓ąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄ, ąĮąŠ čü ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čé.ąĄ. čü čäčĆą░ąĘą░ą╝ąĖ, ąĮąĄ čāčćą░čüčéą▓čāčÄčēąĖą╝ąĖ čĆą░ąĮąĄąĄ ą▓ ąŠą▒čāč湥ąĮąĖąĖ čüąĖčüč鹥ą╝čŗ.

ą¤ąŠ ąĮą░ą▒ą╗čÄą┤ąĄąĮąĖčÄ ą░ą▓č鹊čĆą░, č湥ą╝ ą▒ąŠą╗čīčłąĄ ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄą╝ąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░, č鹥ą╝ ąĮąĖąČąĄ ą┐čĆąŠčåąĄąĮčé ąŠčłąĖą▒ąŠą║ čüąĖčüč鹥ą╝čŗ, ą┐čĆąĖ čŹč鹊ą╝ ą▓čĆąĄą╝čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ. ą¤čĆąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĖ ą▓čĆąĄą╝ąĄąĮąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┤ą╗čÅ ąŠą┤ąĮąŠą┐ą╗ą░čéąĮąŠą│ąŠ ąĖ ąĮą░čüč鹊ą╗čīąĮąŠą│ąŠ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ ą╝ąŠąČąĮąŠ ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čĆą░ą▒ąŠčéą░ąĄčé ą▓ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ. ąÆ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ą┤ą╗čÅ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ čüąŠąĘą┤ą░ąĮąĖčÅ čŹčéą░ą╗ąŠąĮąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮą░čüč鹊ą╗čīąĮąŠą│ąŠ ą║ąŠą╝ą┐čīčÄč鹥čĆą░. ąŚą░č鹥ą╝ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čäą░ą╣ą╗čŗ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐ąĄčĆąĄąĮąŠčüčÅčéčüčÅ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┤ą╗čÅ ąĖčģ ą┤ą░ą╗čīąĮąĄą╣čłąĄą│ąŠ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ. ą×ą┤ąĮą░ą║ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┤ąĮąŠą┐ą╗ą░čéąĮąŠą│ąŠ ą║ąŠą╝ą┐čīčÄč鹥čĆą░ ą▓ ą║ą░č湥čüčéą▓ąĄ čüąĖčüč鹥ą╝čŗ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┤ąĖą║č鹊čĆą░ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą╝ą░čüčłčéą░ą▒ąĄ ą▓čĆąĄą╝ąĄąĮąĖ ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą┐ąŠ ą╝ąĮąĄąĮąĖčÄ ą░ą▓č鹊čĆą░, ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ. ąØąĄąŠą▒čģąŠą┤ąĖą╝ą░ ą║ą░ą║ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▒ąŠą╗ąĄąĄ ą▒čŗčüčéčĆąŠą╣ ą┐ąŠčüč鹊čÅąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ), čéą░ą║ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮą░čÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐čāč鹥ą╝ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ąĖ ą┐ą╗ą░čéč乊čĆą╝čŗ ALIZE. ąŻą╝ąĄąĮčīčłąĄąĮąĖąĄ ąČąĄ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĪąōąĀ ą▓ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┤ą╗čÅ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ čüą╝čŗčüą╗ą░ ąĮąĄ ąĖą╝ąĄąĄčé, čé.ą║. čŹč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠą╝čā čāą▓ąĄą╗ąĖč湥ąĮąĖčÄ ąŠčłąĖą▒ąŠą║ ą╗ąŠąČąĮąŠą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ. ą×ą┐čéąĖą╝ą░ą╗čīąĮčŗą╝, ą┐ąŠ ą╝ąĮąĄąĮąĖčÄ ą░ą▓č鹊čĆą░, čÅą▓ą╗čÅąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ ąĪąōąĀ, čĆą░ą▓ąĮąŠąĄ 1024. ąĪą╗ąĄą┤čāąĄčé čéą░ą║ąČąĄ ąŠčéą╝ąĄčéąĖčéčī, čćč鹊 ą▓ąĄčĆąĖčäąĖą║ą░čåąĖčÅ čĆąĄčćąĖ ąĮąĄ čéčĆąĄą▒čāąĄčé ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┐ąŠą┤ąŠą▒ąĖčÅ ą▓čģąŠą┤ąĮąŠą│ąŠ čĆąĄč湥ą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┤ąĖą║č鹊čĆą░ ą▓ąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄ. ąöą╗čÅ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ ą┤ąŠčüčéą░č鹊čćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé ą┐ąŠą┤ąŠą▒ąĖčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą┤ąĮąŠą╣ ą│ąŠą╗ąŠčüąŠą▓ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ, ąĮą░ ąĖą┤ąĄąĮčéąĖčćąĮąŠčüčéčī ą║ąŠč鹊čĆąŠą╣ ą┐čĆąĄč鹥ąĮą┤čāąĄčé ą▓ąĄčĆąĖčäąĖčåąĖčĆčāąĄą╝čŗą╣ ą┤ąĖą║č鹊čĆ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▒čāą┤ąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą╗ąĄą│č湥 ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ą░čĆą░ą╝ąĄčéčĆčŗ čüąĖčüč鹥ą╝čŗ ą┤ą╗čÅ ąĄąĄ čĆą░ą▒ąŠčéčŗ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą╝ą░čüčłčéą░ą▒ąĄ ą▓čĆąĄą╝ąĄąĮąĖ čü ą┐čĆąĖąĄą╝ą╗ąĄą╝čŗą╝ čāčĆąŠą▓ąĮąĄą╝ ąŠčłąĖą▒ąŠą║ ą▓ąĄčĆąĖčäąĖą║ą░čåąĖąĖ.
ąÆ ąĘą░ą║ą╗čÄč湥ąĮąĖąĄ ąŠčéą╝ąĄčéąĖą╝, čćč鹊 čü čāč湥č鹊ą╝ ą┐ąŠčüč鹊čÅąĮąĮąŠ čāą▓ąĄą╗ąĖčćąĖą▓ą░čÄčēąĄą╣čüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čāčüčéčĆąŠą╣čüčéą▓1 ąĘą░ą┤ą░čćčā ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čĆąĄčćąĖ ąĮą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ ą▓ čüą║ąŠčĆąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé čüą▓ąŠą▒ąŠą┤ąĮąŠ čĆąĄčłą░čéčī ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖą╣ ąĖ čāčēąĄčĆą▒ą░ ą┤ą╗čÅ ą║ą░č湥čüčéą▓ą░ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ.
ąøąĖč鹥čĆą░čéčāčĆą░
ą×ą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ: ą¢čāčĆąĮą░ą╗ "ąóąĄčģąĮąŠą╗ąŠą│ąĖąĖ ąĖ čüčĆąĄą┤čüčéą▓ą░ čüą▓čÅąĘąĖ" #2, 2016
ą¤ąŠčüąĄčēąĄąĮąĖą╣: 4168
ąÉą▓č鹊čĆ
| |||
ąÆ čĆčāą▒čĆąĖą║čā "ąĀąĄčłąĄąĮąĖčÅ ą║ąŠčĆą┐ąŠčĆą░čéąĖą▓ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░" | ąÜ čüą┐ąĖčüą║čā čĆčāą▒čĆąĖą║ | ąÜ čüą┐ąĖčüą║čā ą░ą▓č鹊čĆąŠą▓ | ąÜ čüą┐ąĖčüą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖą╣


